# This gets region (or countries) which are repeated with different NOC values
d1=sqldf("SELECT \
NOC, region,notes,count(*) \
FROM df2 \
GROUP BY region \
HAVING COUNT(*)>1 \
ORDER BY count(*) DESC;",locals())
# this then creates a table with one NOC per region and the original NOC values
# we'll use the new NOC (one per region) a the new index
d2=sqldf("SELECT \
d1.NOC as new_NOC,df2.NOC orig_NOC,df2.region,df2.notes \
FROM d1 \
LEFT JOIN df2 \
ON d1.region=df2.region \
ORDER BY df2.region DESC;",locals())Olympics data with SQL and pandas- create the tables
Splitting up and cleaning Olympic dataset

Introduction
Two csv files (representing two different tables) were imported to databricks.
The main table (athlete_events) consists of 270,000 rows, whereas the unique names in the table are 135,000, or around half the total.
- Lots of columns and lots that are objects,
- so we want to refine this by reducing columns and making it an integer or something smaller than object if possible
- There are some NaN values, particularly for height/weight at earlier games and also for medals
- An athlete can be represented in several rows if they do multiple events or at different games (e.g. Christine Jacoba Aaftink). So we may want a seperate ID that incorporate the athlete and the event/games that is unique
- The TEAM, NOC we only want one identifier and a seperate table for countries
The first step was to split the table up. - First the users are split up based on whether they are male or female and whether they are in the summer or winter games. So split into 4. - Secondly not all data is needed for these athletes table, so instead of 15 columns this is reduced to 9 - Thirdly, the size of these athlete table is reduced by replacing several variables from string to int to reduce the size. Since for example, there is only a limited number of events.
An entity relationship diagram (ERD) of the tables described above was developed as shown below.
Those highlighted in blue and light blue would require additional data, the darkness of blue representing how much new data is needed.
Lucid Chart was used to produce the ERD
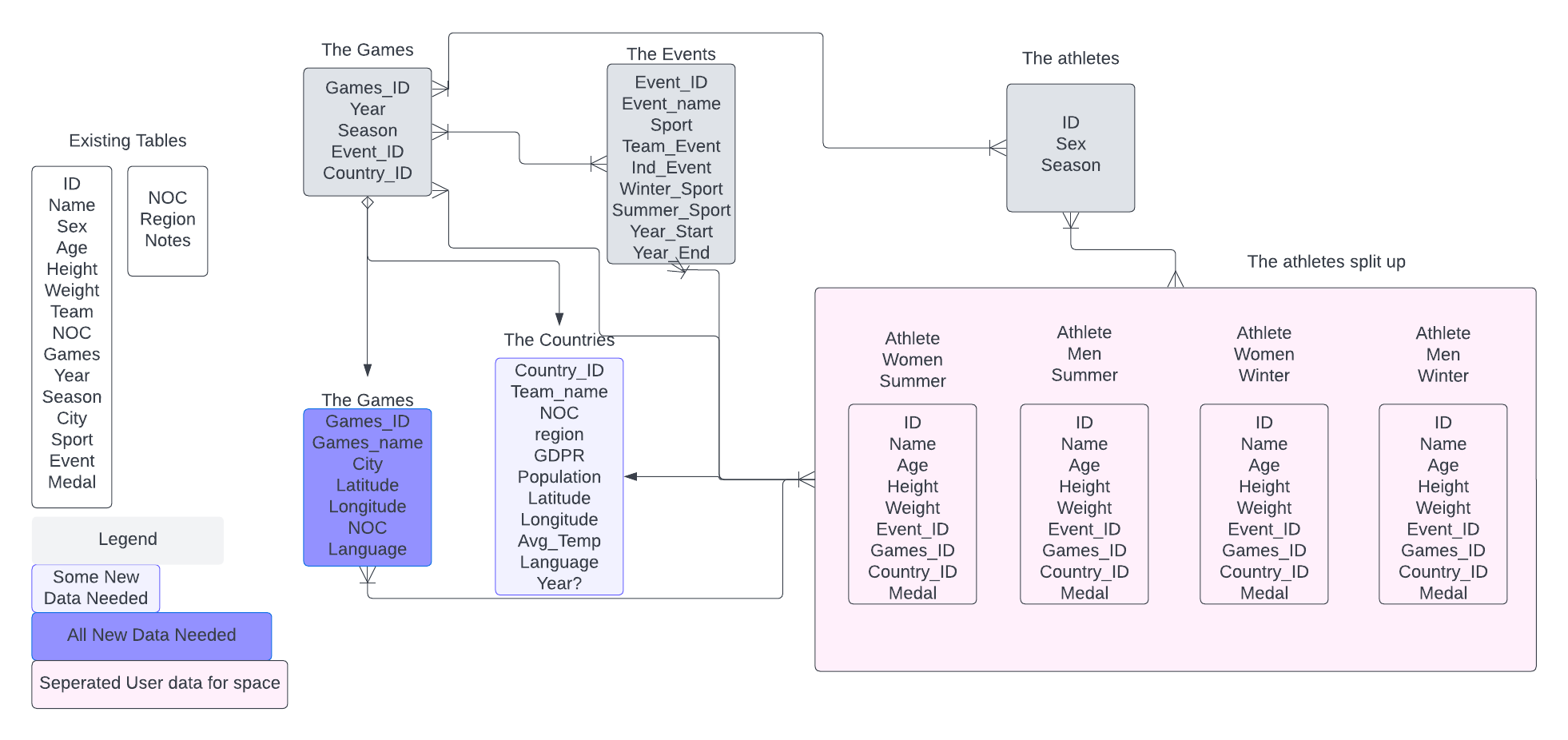
N.B. Most of these are steps not really necessary for this dataset, but I wanted to practice SQL (and pandas). If this was a real world problem I would weigh up the benefits of the splitting in terms of my time and computation to see if it was really necessary.
Creating a country table
In a separate page (https://thomashsimm.com/sql/pandas/python/olympics/2022/07/29/OlympicsSQL_createCountryDF.html) I show how I created the country table.
I also made some slight changes to the two main DataFrames df2 and df. Basically just to change the country label and add unique athlete and athlete + event ids
df= df.reset_index()
df.rename(columns={'index':'event_athlete_ID','ID':'athlete_ID'},inplace=True)
The main part is to get rid of some duplicate NOC values, mostly correct but will not work in some regards e.g. China and Hong Kong.
# then replace the regions with several NOC values with the new one
for i,old_NOC in enumerate(d2.orig_NOC):
df.loc[df.NOC==old_NOC,'NOC']=d2.loc[i,'new_NOC']
df2.loc[df2.NOC==old_NOC,'NOC']=d2.loc[i,'new_NOC']df= pd.read_csv("athlete_events.csv")
try:
df.drop(columns='Unnamed: 0',inplace=True)
except:
pass
df2=pd.read_csv("noc_regions.csv")Look at the data
# !pip install pandasql
import pandas as pd
from pandasql import sqldf
import matplotlib.pyplot as plt
import re
df| event_athlete_ID | athlete_ID | Name | Sex | Age | Height | Weight | Team | NOC | Games | Year | Season | City | Sport | Event | Medal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | A Dijiang | M | 24.0 | 180.0 | 80.0 | China | CHN | 1992 Summer | 1992 | Summer | Barcelona | Basketball | Basketball Men's Basketball | NaN |
| 1 | 1 | 2 | A Lamusi | M | 23.0 | 170.0 | 60.0 | China | CHN | 2012 Summer | 2012 | Summer | London | Judo | Judo Men's Extra-Lightweight | NaN |
| 2 | 2 | 3 | Gunnar Nielsen Aaby | M | 24.0 | NaN | NaN | Denmark | DEN | 1920 Summer | 1920 | Summer | Antwerpen | Football | Football Men's Football | NaN |
| 3 | 3 | 4 | Edgar Lindenau Aabye | M | 34.0 | NaN | NaN | Denmark/Sweden | DEN | 1900 Summer | 1900 | Summer | Paris | Tug-Of-War | Tug-Of-War Men's Tug-Of-War | Gold |
| 4 | 4 | 5 | Christine Jacoba Aaftink | F | 21.0 | 185.0 | 82.0 | Netherlands | NED | 1988 Winter | 1988 | Winter | Calgary | Speed Skating | Speed Skating Women's 500 metres | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 271111 | 271111 | 135569 | Andrzej ya | M | 29.0 | 179.0 | 89.0 | Poland-1 | POL | 1976 Winter | 1976 | Winter | Innsbruck | Luge | Luge Mixed (Men)'s Doubles | NaN |
| 271112 | 271112 | 135570 | Piotr ya | M | 27.0 | 176.0 | 59.0 | Poland | POL | 2014 Winter | 2014 | Winter | Sochi | Ski Jumping | Ski Jumping Men's Large Hill, Individual | NaN |
| 271113 | 271113 | 135570 | Piotr ya | M | 27.0 | 176.0 | 59.0 | Poland | POL | 2014 Winter | 2014 | Winter | Sochi | Ski Jumping | Ski Jumping Men's Large Hill, Team | NaN |
| 271114 | 271114 | 135571 | Tomasz Ireneusz ya | M | 30.0 | 185.0 | 96.0 | Poland | POL | 1998 Winter | 1998 | Winter | Nagano | Bobsleigh | Bobsleigh Men's Four | NaN |
| 271115 | 271115 | 135571 | Tomasz Ireneusz ya | M | 34.0 | 185.0 | 96.0 | Poland | POL | 2002 Winter | 2002 | Winter | Salt Lake City | Bobsleigh | Bobsleigh Men's Four | NaN |
271116 rows × 16 columns
df.dtypesevent_athlete_ID int64
athlete_ID int64
Name object
Sex object
Age float64
Height float64
Weight float64
Team object
NOC object
Games object
Year int64
Season object
City object
Sport object
Event object
Medal object
dtype: objectdf.describe()| event_athlete_ID | athlete_ID | Age | Height | Weight | Year | |
|---|---|---|---|---|---|---|
| count | 271116.000000 | 271116.000000 | 261642.000000 | 210945.000000 | 208241.000000 | 271116.000000 |
| mean | 135557.500000 | 68248.954396 | 25.556898 | 175.338970 | 70.702393 | 1978.378480 |
| std | 78264.592128 | 39022.286345 | 6.393561 | 10.518462 | 14.348020 | 29.877632 |
| min | 0.000000 | 1.000000 | 10.000000 | 127.000000 | 25.000000 | 1896.000000 |
| 25% | 67778.750000 | 34643.000000 | 21.000000 | 168.000000 | 60.000000 | 1960.000000 |
| 50% | 135557.500000 | 68205.000000 | 24.000000 | 175.000000 | 70.000000 | 1988.000000 |
| 75% | 203336.250000 | 102097.250000 | 28.000000 | 183.000000 | 79.000000 | 2002.000000 |
| max | 271115.000000 | 135571.000000 | 97.000000 | 226.000000 | 214.000000 | 2016.000000 |
Create all_athletes table
Because we are splitting the athlete data based on Summer/Winter and Male/Female we need a folder to be able to join or access different parts of the individual athlete tables.
df= df.reset_index()
df.rename(columns={'index':'event_athlete_ID','ID':'athlete_ID'},inplace=True)
df.head(10)| event_athlete_ID | event_athlete_ID | athlete_ID | Name | Sex | Age | Height | Weight | Team | NOC | Games | Year | Season | City | Sport | Event | Medal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | A Dijiang | M | 24.0 | 180.0 | 80.0 | China | CHN | 1992 Summer | 1992 | Summer | Barcelona | Basketball | Basketball Men's Basketball | NaN |
| 1 | 1 | 1 | 2 | A Lamusi | M | 23.0 | 170.0 | 60.0 | China | CHN | 2012 Summer | 2012 | Summer | London | Judo | Judo Men's Extra-Lightweight | NaN |
| 2 | 2 | 2 | 3 | Gunnar Nielsen Aaby | M | 24.0 | NaN | NaN | Denmark | DEN | 1920 Summer | 1920 | Summer | Antwerpen | Football | Football Men's Football | NaN |
| 3 | 3 | 3 | 4 | Edgar Lindenau Aabye | M | 34.0 | NaN | NaN | Denmark/Sweden | DEN | 1900 Summer | 1900 | Summer | Paris | Tug-Of-War | Tug-Of-War Men's Tug-Of-War | Gold |
| 4 | 4 | 4 | 5 | Christine Jacoba Aaftink | F | 21.0 | 185.0 | 82.0 | Netherlands | NED | 1988 Winter | 1988 | Winter | Calgary | Speed Skating | Speed Skating Women's 500 metres | NaN |
| 5 | 5 | 5 | 5 | Christine Jacoba Aaftink | F | 21.0 | 185.0 | 82.0 | Netherlands | NED | 1988 Winter | 1988 | Winter | Calgary | Speed Skating | Speed Skating Women's 1,000 metres | NaN |
| 6 | 6 | 6 | 5 | Christine Jacoba Aaftink | F | 25.0 | 185.0 | 82.0 | Netherlands | NED | 1992 Winter | 1992 | Winter | Albertville | Speed Skating | Speed Skating Women's 500 metres | NaN |
| 7 | 7 | 7 | 5 | Christine Jacoba Aaftink | F | 25.0 | 185.0 | 82.0 | Netherlands | NED | 1992 Winter | 1992 | Winter | Albertville | Speed Skating | Speed Skating Women's 1,000 metres | NaN |
| 8 | 8 | 8 | 5 | Christine Jacoba Aaftink | F | 27.0 | 185.0 | 82.0 | Netherlands | NED | 1994 Winter | 1994 | Winter | Lillehammer | Speed Skating | Speed Skating Women's 500 metres | NaN |
| 9 | 9 | 9 | 5 | Christine Jacoba Aaftink | F | 27.0 | 185.0 | 82.0 | Netherlands | NED | 1994 Winter | 1994 | Winter | Lillehammer | Speed Skating | Speed Skating Women's 1,000 metres | NaN |
df_all_athletes=df[['event_athlete_ID','athlete_ID','Name','Sex','Season']]
df_all_athletes | event_athlete_ID | event_athlete_ID | athlete_ID | Name | Sex | Season | |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | A Dijiang | M | Summer |
| 1 | 1 | 1 | 2 | A Lamusi | M | Summer |
| 2 | 2 | 2 | 3 | Gunnar Nielsen Aaby | M | Summer |
| 3 | 3 | 3 | 4 | Edgar Lindenau Aabye | M | Summer |
| 4 | 4 | 4 | 5 | Christine Jacoba Aaftink | F | Winter |
| ... | ... | ... | ... | ... | ... | ... |
| 271111 | 271111 | 271111 | 135569 | Andrzej ya | M | Winter |
| 271112 | 271112 | 271112 | 135570 | Piotr ya | M | Winter |
| 271113 | 271113 | 271113 | 135570 | Piotr ya | M | Winter |
| 271114 | 271114 | 271114 | 135571 | Tomasz Ireneusz ya | M | Winter |
| 271115 | 271115 | 271115 | 135571 | Tomasz Ireneusz ya | M | Winter |
271116 rows × 6 columns
Creating an Events Table
In this table the individual events are displayed. e.g. 100m Mens Sprint Athletics or Womens Football
print("There are {} unique sports and {} unique events ".format(len(pd.unique(df.Sport)), len(pd.unique(df.Event))))There are 66 unique sports and 765 unique events Because of the way that events are named they won’t be duplicated, e.g. 400m breaststroke swimming will be different from 400m athletics running because the name is prefixed with Athletics Women, Swimming Men etc
Instead of using one hot encoding (get_dummies for pandas as done with medals) we want a different number for each unique event in one column. To do this we can use factorize
aa=pd.factorize(df.ColumnCheck)
will give us a variable where - aa[0] is a list of numbers of length of rows in df, where each value represents a different event - aa[1] is then a list of the events of length of the unique events, aa[1][0] is event = 0, aa[1][1] is event = 1 etc - so below aa[1][0] = ‘Basketball Men’s Basketball’ and each row in the df with this event will have a 0 in aa[0]
event_details=pd.factorize(df.Event)
event_details[1][0:100], event_details[0][1:10](Index(['Basketball Men's Basketball', 'Judo Men's Extra-Lightweight',
'Football Men's Football', 'Tug-Of-War Men's Tug-Of-War',
'Speed Skating Women's 500 metres',
'Speed Skating Women's 1,000 metres',
'Cross Country Skiing Men's 10 kilometres',
'Cross Country Skiing Men's 50 kilometres',
'Cross Country Skiing Men's 10/15 kilometres Pursuit',
'Cross Country Skiing Men's 4 x 10 kilometres Relay',
'Cross Country Skiing Men's 30 kilometres',
'Athletics Women's 100 metres',
'Athletics Women's 4 x 100 metres Relay', 'Ice Hockey Men's Ice Hockey',
'Swimming Men's 400 metres Freestyle', 'Badminton Men's Singles',
'Sailing Women's Windsurfer', 'Biathlon Women's 7.5 kilometres Sprint',
'Swimming Men's 200 metres Breaststroke',
'Swimming Men's 400 metres Breaststroke',
'Gymnastics Men's Individual All-Around',
'Gymnastics Men's Team All-Around', 'Gymnastics Men's Floor Exercise',
'Gymnastics Men's Horse Vault', 'Gymnastics Men's Parallel Bars',
'Gymnastics Men's Horizontal Bar', 'Gymnastics Men's Rings',
'Gymnastics Men's Pommelled Horse', 'Athletics Men's Shot Put',
'Art Competitions Mixed Sculpturing, Unknown Event',
'Alpine Skiing Men's Downhill', 'Alpine Skiing Men's Super G',
'Alpine Skiing Men's Giant Slalom', 'Alpine Skiing Men's Slalom',
'Alpine Skiing Men's Combined', 'Handball Women's Handball',
'Weightlifting Women's Super-Heavyweight',
'Wrestling Men's Light-Heavyweight, Greco-Roman',
'Speed Skating Men's 500 metres', 'Speed Skating Men's 1,500 metres',
'Gymnastics Men's Team All-Around, Free System', 'Luge Women's Singles',
'Water Polo Men's Water Polo', 'Sailing Mixed Three Person Keelboat',
'Hockey Women's Hockey', 'Rowing Men's Lightweight Double Sculls',
'Athletics Men's Pole Vault', 'Athletics Men's High Jump',
'Sailing Men's Two Person Dinghy', 'Athletics Men's 1,500 metres',
'Bobsleigh Men's Four', 'Swimming Men's 100 metres Butterfly',
'Swimming Men's 200 metres Butterfly',
'Swimming Men's 4 x 100 metres Medley Relay',
'Football Women's Football', 'Fencing Men's Foil, Individual',
'Fencing Men's epee, Individual', 'Fencing Men's epee, Team',
'Speed Skating Men's 5,000 metres', 'Speed Skating Men's 10,000 metres',
'Sailing Mixed 8 metres', 'Equestrianism Mixed Jumping, Individual',
'Cross Country Skiing Men's 15 kilometres',
'Shooting Men's Small-Bore Rifle, Prone, 50 metres',
'Shooting Men's Rapid-Fire Pistol, 25 metres', 'Shooting Men's Trap',
'Athletics Men's 4 x 100 metres Relay', 'Athletics Men's Long Jump',
'Boxing Men's Light-Welterweight', 'Athletics Women's Javelin Throw',
'Wrestling Men's Heavyweight, Freestyle', 'Taekwondo Men's Flyweight',
'Boxing Men's Heavyweight', 'Athletics Men's 5,000 metres',
'Cycling Men's Road Race, Individual', 'Cycling Men's Road Race, Team',
'Weightlifting Men's Lightweight', 'Weightlifting Men's Middleweight',
'Rowing Men's Coxless Pairs', 'Judo Men's Half-Middleweight',
'Taekwondo Women's Flyweight', 'Boxing Men's Flyweight',
'Basketball Women's Basketball', 'Diving Men's Platform',
'Canoeing Men's Canadian Doubles, 500 metres',
'Canoeing Men's Canadian Doubles, 1,000 metres',
'Canoeing Men's Kayak Fours, 1,000 metres', 'Handball Men's Handball',
'Rowing Women's Coxless Pairs', 'Boxing Men's Middleweight',
'Judo Men's Lightweight', 'Boxing Men's Featherweight',
'Tennis Men's Doubles', 'Shooting Mixed Skeet',
'Wrestling Men's Featherweight, Freestyle',
'Sailing Mixed Two Person Heavyweight Dinghy',
'Athletics Women's Shot Put', 'Rowing Men's Coxed Eights',
'Cycling Women's Sprint', 'Cycling Women's 500 metres Time Trial'],
dtype='object'),
array([1, 2, 3, 4, 5, 4, 5, 4, 5], dtype=int64))df.insert(2,'event_id',event_details[0])
df.head(10)| event_athlete_ID | event_athlete_ID | event_id | athlete_ID | Name | Sex | Age | Height | Weight | Team | NOC | Games | Year | Season | City | Sport | Event | Medal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 | A Dijiang | M | 24.0 | 180.0 | 80.0 | China | CHN | 1992 Summer | 1992 | Summer | Barcelona | Basketball | Basketball Men's Basketball | NaN |
| 1 | 1 | 1 | 1 | 2 | A Lamusi | M | 23.0 | 170.0 | 60.0 | China | CHN | 2012 Summer | 2012 | Summer | London | Judo | Judo Men's Extra-Lightweight | NaN |
| 2 | 2 | 2 | 2 | 3 | Gunnar Nielsen Aaby | M | 24.0 | NaN | NaN | Denmark | DEN | 1920 Summer | 1920 | Summer | Antwerpen | Football | Football Men's Football | NaN |
| 3 | 3 | 3 | 3 | 4 | Edgar Lindenau Aabye | M | 34.0 | NaN | NaN | Denmark/Sweden | DEN | 1900 Summer | 1900 | Summer | Paris | Tug-Of-War | Tug-Of-War Men's Tug-Of-War | Gold |
| 4 | 4 | 4 | 4 | 5 | Christine Jacoba Aaftink | F | 21.0 | 185.0 | 82.0 | Netherlands | NED | 1988 Winter | 1988 | Winter | Calgary | Speed Skating | Speed Skating Women's 500 metres | NaN |
| 5 | 5 | 5 | 5 | 5 | Christine Jacoba Aaftink | F | 21.0 | 185.0 | 82.0 | Netherlands | NED | 1988 Winter | 1988 | Winter | Calgary | Speed Skating | Speed Skating Women's 1,000 metres | NaN |
| 6 | 6 | 6 | 4 | 5 | Christine Jacoba Aaftink | F | 25.0 | 185.0 | 82.0 | Netherlands | NED | 1992 Winter | 1992 | Winter | Albertville | Speed Skating | Speed Skating Women's 500 metres | NaN |
| 7 | 7 | 7 | 5 | 5 | Christine Jacoba Aaftink | F | 25.0 | 185.0 | 82.0 | Netherlands | NED | 1992 Winter | 1992 | Winter | Albertville | Speed Skating | Speed Skating Women's 1,000 metres | NaN |
| 8 | 8 | 8 | 4 | 5 | Christine Jacoba Aaftink | F | 27.0 | 185.0 | 82.0 | Netherlands | NED | 1994 Winter | 1994 | Winter | Lillehammer | Speed Skating | Speed Skating Women's 500 metres | NaN |
| 9 | 9 | 9 | 5 | 5 | Christine Jacoba Aaftink | F | 27.0 | 185.0 | 82.0 | Netherlands | NED | 1994 Winter | 1994 | Winter | Lillehammer | Speed Skating | Speed Skating Women's 1,000 metres | NaN |
event_details=pd.factorize(df.Event)
df_event = pd.DataFrame(event_details[1])
df_event| 0 | |
|---|---|
| 0 | Basketball Men's Basketball |
| 1 | Judo Men's Extra-Lightweight |
| 2 | Football Men's Football |
| 3 | Tug-Of-War Men's Tug-Of-War |
| 4 | Speed Skating Women's 500 metres |
| ... | ... |
| 760 | Weightlifting Men's All-Around Dumbbell Contest |
| 761 | Archery Men's Au Chapelet, 33 metres |
| 762 | Archery Men's Au Cordon Dore, 33 metres |
| 763 | Archery Men's Target Archery, 28 metres, Indiv... |
| 764 | Aeronautics Mixed Aeronautics |
765 rows × 1 columns
df_event = df[['Sport','Event','Sex','Season']]
event_details=pd.factorize(df.Sport)
df_event.insert(0,'sport_id',event_details[0])
event_details=pd.factorize(df.Event)
df_event.insert(0,'event_id',event_details[0])
df_event| event_id | sport_id | Sport | Event | Sex | Season | |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | Basketball | Basketball Men's Basketball | M | Summer |
| 1 | 1 | 1 | Judo | Judo Men's Extra-Lightweight | M | Summer |
| 2 | 2 | 2 | Football | Football Men's Football | M | Summer |
| 3 | 3 | 3 | Tug-Of-War | Tug-Of-War Men's Tug-Of-War | M | Summer |
| 4 | 4 | 4 | Speed Skating | Speed Skating Women's 500 metres | F | Winter |
| ... | ... | ... | ... | ... | ... | ... |
| 271111 | 461 | 18 | Luge | Luge Mixed (Men)'s Doubles | M | Winter |
| 271112 | 418 | 48 | Ski Jumping | Ski Jumping Men's Large Hill, Individual | M | Winter |
| 271113 | 419 | 48 | Ski Jumping | Ski Jumping Men's Large Hill, Team | M | Winter |
| 271114 | 50 | 22 | Bobsleigh | Bobsleigh Men's Four | M | Winter |
| 271115 | 50 | 22 | Bobsleigh | Bobsleigh Men's Four | M | Winter |
271116 rows × 6 columns
df_event = df_event.drop_duplicates().reset_index(drop=True)
df_event#[df_event.Sex=='F'].head(30)| event_id | sport_id | Sport | Event | Sex | Season | |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | Basketball | Basketball Men's Basketball | M | Summer |
| 1 | 1 | 1 | Judo | Judo Men's Extra-Lightweight | M | Summer |
| 2 | 2 | 2 | Football | Football Men's Football | M | Summer |
| 3 | 3 | 3 | Tug-Of-War | Tug-Of-War Men's Tug-Of-War | M | Summer |
| 4 | 4 | 4 | Speed Skating | Speed Skating Women's 500 metres | F | Winter |
| ... | ... | ... | ... | ... | ... | ... |
| 824 | 221 | 10 | Sailing | Sailing Mixed 7 metres | F | Summer |
| 825 | 333 | 10 | Sailing | Sailing Mixed 6 metres | F | Summer |
| 826 | 764 | 65 | Aeronautics | Aeronautics Mixed Aeronautics | M | Summer |
| 827 | 677 | 13 | Art Competitions | Art Competitions Mixed Sculpturing, Medals And... | F | Summer |
| 828 | 648 | 13 | Art Competitions | Art Competitions Mixed Unknown Event | F | Summer |
829 rows × 6 columns
An additional columns in event_table
Lets add a column representing if the sport is a team sport or individual. We can’t do this on the unique members of a team in that event because the team can have multiple members in an individual event. Instead, we can look for how many people took the gold medal. Should work for most circumstances as the gold shouldn’t be shared- so if 2 people won gold it should represent a team sport of 2 people.
This is a little convoluted so I’ll do it in two steps in SQL. One way to calculate and one to join this new table back in with df_event
df_event_temp=sqldf("SELECT \
event_id,event,num_athletes \
FROM \
(SELECT \
event, \
event_id, \
COUNT(*) as num_athletes \
FROM df \
WHERE Medal='Gold' \
GROUP BY Team, event_id, Games \
ORDER BY event_id \
) \
GROUP BY event_id \
;", locals())
df_event_temp| event_id | event | num_athletes | |
|---|---|---|---|
| 0 | 0 | Basketball Men's Basketball | 12 |
| 1 | 1 | Judo Men's Extra-Lightweight | 1 |
| 2 | 2 | Football Men's Football | 16 |
| 3 | 3 | Tug-Of-War Men's Tug-Of-War | 6 |
| 4 | 4 | Speed Skating Women's 500 metres | 1 |
| ... | ... | ... | ... |
| 745 | 760 | Weightlifting Men's All-Around Dumbbell Contest | 1 |
| 746 | 761 | Archery Men's Au Chapelet, 33 metres | 1 |
| 747 | 762 | Archery Men's Au Cordon Dore, 33 metres | 1 |
| 748 | 763 | Archery Men's Target Archery, 28 metres, Indiv... | 1 |
| 749 | 764 | Aeronautics Mixed Aeronautics | 1 |
750 rows × 3 columns
df_event_temp = sqldf("SELECT \
d.event_id, \
d.sport_id, \
d.Sport, \
d.Event, \
d.Sex, \
d.Season, \
t.num_athletes \
FROM df_event as d \
LEFT JOIN \
df_event_temp as t \
ON \
t.event_id=d.event_id \
ORDER BY d.event_id \
;",locals())
# df_event_temp[((df_event_temp.Sex=='F') & (df_event_temp.Season=='Winter'))].head(30)
df_event=df_event_tempAnd make the last column int not float (CAST didn’t seem to work perhaps due to NaN values?)
df_event.fillna(0,inplace=True)
df_event = df_event.astype({'num_athletes':'int'})# sanity check
df_event[((df_event['num_athletes']==4) & (df_event['Season']=='Winter'))]| event_id | sport_id | Sport | Event | Sex | Season | num_athletes | |
|---|---|---|---|---|---|---|---|
| 9 | 9 | 5 | Cross Country Skiing | Cross Country Skiing Men's 4 x 10 kilometres R... | M | Winter | 4 |
| 53 | 50 | 22 | Bobsleigh | Bobsleigh Men's Four | M | Winter | 4 |
| 215 | 204 | 40 | Nordic Combined | Nordic Combined Men's Team | M | Winter | 4 |
| 238 | 226 | 11 | Biathlon | Biathlon Men's 4 x 7.5 kilometres Relay | M | Winter | 4 |
| 274 | 259 | 11 | Biathlon | Biathlon Mixed 2 x 6 kilometres and 2 x 7.5 ki... | M | Winter | 4 |
| 275 | 259 | 11 | Biathlon | Biathlon Mixed 2 x 6 kilometres and 2 x 7.5 ki... | F | Winter | 4 |
| 330 | 310 | 11 | Biathlon | Biathlon Women's 4 x 7.5 kilometres Relay | F | Winter | 4 |
| 451 | 419 | 48 | Ski Jumping | Ski Jumping Men's Large Hill, Team | M | Winter | 4 |
| 470 | 435 | 52 | Short Track Speed Skating | Short Track Speed Skating Men's 5,000 metres R... | M | Winter | 4 |
| 478 | 443 | 11 | Biathlon | Biathlon Women's 4 x 6 kilometres Relay | F | Winter | 4 |
| 504 | 466 | 5 | Cross Country Skiing | Cross Country Skiing Women's 4 x 5 kilometres ... | F | Winter | 4 |
| 510 | 472 | 22 | Bobsleigh | Bobsleigh Men's Four/Five | M | Winter | 4 |
| 533 | 492 | 52 | Short Track Speed Skating | Short Track Speed Skating Women's 3,000 metres... | F | Winter | 4 |
| 615 | 572 | 18 | Luge | Luge Mixed Team Relay | M | Winter | 4 |
| 616 | 572 | 18 | Luge | Luge Mixed Team Relay | F | Winter | 4 |
| 640 | 594 | 59 | Military Ski Patrol | Military Ski Patrol Men's Military Ski Patrol | M | Winter | 4 |
df[df.event_id==572][['Sport','Event','Sex']].tail(6),df_event[df_event.event_id==572]( Sport Event Sex
255927 Luge Luge Mixed Team Relay M
258882 Luge Luge Mixed Team Relay M
262369 Luge Luge Mixed Team Relay F
267369 Luge Luge Mixed Team Relay M
268477 Luge Luge Mixed Team Relay M
270261 Luge Luge Mixed Team Relay M,
event_id sport_id Sport Event Sex Season num_athletes
615 572 18 Luge Luge Mixed Team Relay M Winter 4
616 572 18 Luge Luge Mixed Team Relay F Winter 4)Add a Games table
The games table is used to give information about a particular Olympic games including - Where it was staged - Is it a summer or winter games - The year it was staged
Using the same methodology as before we want to - create a unique id for the games - replace this in the athlete tables - add a new table with the unique id and additional information about the particular games
This is more complex than the events table because we want to add additional data about the cities where the games were held. This data is obtained from wikipedia as before. So some of the methodology used in creating the country table is used here.
There’s a strange thing that there are two summer games in one year
df=df.sort_values(by=['Year','City'])# event_details=pd.factorize(pd.lib.fast_zip([df.Games, df.City]))
tuples = df[['Games', 'City']].apply(tuple, axis=1)
event_details = pd.factorize( tuples )
event_details[1][0:10], event_details[0][1:10],len(event_details[1]),len(event_details[0])(Index([ ('1896 Summer', 'Athina'), ('1900 Summer', 'Paris'),
('1904 Summer', 'St. Louis'), ('1906 Summer', 'Athina'),
('1908 Summer', 'London'), ('1912 Summer', 'Stockholm'),
('1920 Summer', 'Antwerpen'), ('1924 Winter', 'Chamonix'),
('1924 Summer', 'Paris'), ('1928 Summer', 'Amsterdam')],
dtype='object'),
array([0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int64),
52,
271116)df.insert(3,'games_id',event_details[0])
df| event_athlete_ID | event_athlete_ID | event_id | games_id | athlete_ID | Name | Sex | Age | Height | Weight | Team | NOC | Games | Year | Season | City | Sport | Event | Medal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3079 | 3079 | 3079 | 191 | 0 | 1724 | Aristidis Akratopoulos | M | NaN | NaN | NaN | Greece | CRT | 1896 Summer | 1896 | Summer | Athina | Tennis | Tennis Men's Singles | NaN |
| 3080 | 3080 | 3080 | 92 | 0 | 1724 | Aristidis Akratopoulos | M | NaN | NaN | NaN | Greece-3 | CRT | 1896 Summer | 1896 | Summer | Athina | Tennis | Tennis Men's Doubles | NaN |
| 3081 | 3081 | 3081 | 191 | 0 | 1725 | Konstantinos "Kostas" Akratopoulos | M | NaN | NaN | NaN | Greece | CRT | 1896 Summer | 1896 | Summer | Athina | Tennis | Tennis Men's Singles | NaN |
| 3082 | 3082 | 3082 | 92 | 0 | 1725 | Konstantinos "Kostas" Akratopoulos | M | NaN | NaN | NaN | Greece-3 | CRT | 1896 Summer | 1896 | Summer | Athina | Tennis | Tennis Men's Doubles | NaN |
| 7348 | 7348 | 7348 | 100 | 0 | 4113 | Anastasios Andreou | M | NaN | NaN | NaN | Greece | CRT | 1896 Summer | 1896 | Summer | Athina | Athletics | Athletics Men's 110 metres Hurdles | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 271024 | 271024 | 271024 | 15 | 51 | 135528 | Marc Zwiebler | M | 32.0 | 181.0 | 75.0 | Germany | FRG | 2016 Summer | 2016 | Summer | Rio de Janeiro | Badminton | Badminton Men's Singles | NaN |
| 271053 | 271053 | 271053 | 11 | 51 | 135547 | Viktoriya Viktorovna Zyabkina | F | 23.0 | 174.0 | 62.0 | Kazakhstan | KAZ | 2016 Summer | 2016 | Summer | Rio de Janeiro | Athletics | Athletics Women's 100 metres | NaN |
| 271054 | 271054 | 271054 | 174 | 51 | 135547 | Viktoriya Viktorovna Zyabkina | F | 23.0 | 174.0 | 62.0 | Kazakhstan | KAZ | 2016 Summer | 2016 | Summer | Rio de Janeiro | Athletics | Athletics Women's 200 metres | NaN |
| 271055 | 271055 | 271055 | 12 | 51 | 135547 | Viktoriya Viktorovna Zyabkina | F | 23.0 | 174.0 | 62.0 | Kazakhstan | KAZ | 2016 Summer | 2016 | Summer | Rio de Janeiro | Athletics | Athletics Women's 4 x 100 metres Relay | NaN |
| 271110 | 271110 | 271110 | 82 | 51 | 135568 | Olga Igorevna Zyuzkova | F | 33.0 | 171.0 | 69.0 | Belarus | BLR | 2016 Summer | 2016 | Summer | Rio de Janeiro | Basketball | Basketball Women's Basketball | NaN |
271116 rows × 19 columns
df[['games_id','Games','City']].groupby(['games_id','Games']).count()| City | ||
|---|---|---|
| games_id | Games | |
| 0 | 1896 Summer | 380 |
| 1 | 1900 Summer | 1936 |
| 2 | 1904 Summer | 1301 |
| 3 | 1906 Summer | 1733 |
| 4 | 1908 Summer | 3101 |
| 5 | 1912 Summer | 4040 |
| 6 | 1920 Summer | 4292 |
| 7 | 1924 Winter | 460 |
| 8 | 1924 Summer | 5233 |
| 9 | 1928 Summer | 4992 |
| 10 | 1928 Winter | 582 |
| 11 | 1932 Winter | 352 |
| 12 | 1932 Summer | 2969 |
| 13 | 1936 Summer | 6506 |
| 14 | 1936 Winter | 895 |
| 15 | 1948 Summer | 6405 |
| 16 | 1948 Winter | 1075 |
| 17 | 1952 Summer | 8270 |
| 18 | 1952 Winter | 1088 |
| 19 | 1956 Winter | 1307 |
| 20 | 1956 Summer | 4829 |
| 21 | 1956 Summer | 298 |
| 22 | 1960 Summer | 8119 |
| 23 | 1960 Winter | 1116 |
| 24 | 1964 Winter | 1778 |
| 25 | 1964 Summer | 7702 |
| 26 | 1968 Winter | 1891 |
| 27 | 1968 Summer | 8588 |
| 28 | 1972 Summer | 10304 |
| 29 | 1972 Winter | 1655 |
| 30 | 1976 Winter | 1861 |
| 31 | 1976 Summer | 8641 |
| 32 | 1980 Winter | 1746 |
| 33 | 1980 Summer | 7191 |
| 34 | 1984 Summer | 9454 |
| 35 | 1984 Winter | 2134 |
| 36 | 1988 Winter | 2639 |
| 37 | 1988 Summer | 12037 |
| 38 | 1992 Winter | 3436 |
| 39 | 1992 Summer | 12977 |
| 40 | 1994 Winter | 3160 |
| 41 | 1996 Summer | 13780 |
| 42 | 1998 Winter | 3605 |
| 43 | 2000 Summer | 13821 |
| 44 | 2002 Winter | 4109 |
| 45 | 2004 Summer | 13443 |
| 46 | 2006 Winter | 4382 |
| 47 | 2008 Summer | 13602 |
| 48 | 2010 Winter | 4402 |
| 49 | 2012 Summer | 12920 |
| 50 | 2014 Winter | 4891 |
| 51 | 2016 Summer | 13688 |
# Load the games table
df_games = pd.read_excel('CitiesOlympics.xlsx',sheet_name=0)
# then sort by year and city like did with df, reset the index
df_games=df_games.sort_values(by=['Year','City']).reset_index(drop=True)
# and replace games_id with new ordered index
df_games['games_id']=df_games.index
## sanity check to see if the two tables for games match
# sanity
dtemp=df[['games_id','Games','City','Year']].groupby(['games_id','Games','City']).count()
dtemp.reset_index(inplace=True)
pd.concat([df_games[['City','Year','Summer']], dtemp ], axis=1)
# | City | Year | Summer | games_id | Games | City | Year | |
|---|---|---|---|---|---|---|---|
| 0 | Athens | 1896 | 1 | 0 | 1896 Summer | Athina | 380 |
| 1 | Paris | 1900 | 1 | 1 | 1900 Summer | Paris | 1936 |
| 2 | St. Louis | 1904 | 1 | 2 | 1904 Summer | St. Louis | 1301 |
| 3 | Athens | 1906 | 1 | 3 | 1906 Summer | Athina | 1733 |
| 4 | London | 1908 | 1 | 4 | 1908 Summer | London | 3101 |
| 5 | Stockholm | 1912 | 1 | 5 | 1912 Summer | Stockholm | 4040 |
| 6 | Antwerp | 1920 | 1 | 6 | 1920 Summer | Antwerpen | 4292 |
| 7 | Chamonix | 1924 | 0 | 7 | 1924 Winter | Chamonix | 460 |
| 8 | Paris | 1924 | 1 | 8 | 1924 Summer | Paris | 5233 |
| 9 | Amsterdam | 1928 | 1 | 9 | 1928 Summer | Amsterdam | 4992 |
| 10 | St. Moritz | 1928 | 0 | 10 | 1928 Winter | Sankt Moritz | 582 |
| 11 | Lake Placid | 1932 | 0 | 11 | 1932 Winter | Lake Placid | 352 |
| 12 | Los Angeles | 1932 | 1 | 12 | 1932 Summer | Los Angeles | 2969 |
| 13 | Berlin | 1936 | 1 | 13 | 1936 Summer | Berlin | 6506 |
| 14 | Garmisch-Partenkirchen | 1936 | 0 | 14 | 1936 Winter | Garmisch-Partenkirchen | 895 |
| 15 | London | 1948 | 1 | 15 | 1948 Summer | London | 6405 |
| 16 | St. Moritz | 1948 | 0 | 16 | 1948 Winter | Sankt Moritz | 1075 |
| 17 | Helsinki | 1952 | 1 | 17 | 1952 Summer | Helsinki | 8270 |
| 18 | Oslo | 1952 | 0 | 18 | 1952 Winter | Oslo | 1088 |
| 19 | Cortina d'Ampezzo | 1956 | 0 | 19 | 1956 Winter | Cortina d'Ampezzo | 1307 |
| 20 | Melbourne | 1956 | 1 | 20 | 1956 Summer | Melbourne | 4829 |
| 21 | Stockholm | 1956 | 0 | 21 | 1956 Summer | Stockholm | 298 |
| 22 | Rome | 1960 | 1 | 22 | 1960 Summer | Roma | 8119 |
| 23 | Squaw Valley | 1960 | 0 | 23 | 1960 Winter | Squaw Valley | 1116 |
| 24 | Innsbruck | 1964 | 0 | 24 | 1964 Winter | Innsbruck | 1778 |
| 25 | Tokyo | 1964 | 1 | 25 | 1964 Summer | Tokyo | 7702 |
| 26 | Grenoble | 1968 | 0 | 26 | 1968 Winter | Grenoble | 1891 |
| 27 | Mexico City | 1968 | 1 | 27 | 1968 Summer | Mexico City | 8588 |
| 28 | Munich | 1972 | 1 | 28 | 1972 Summer | Munich | 10304 |
| 29 | Sapporo | 1972 | 0 | 29 | 1972 Winter | Sapporo | 1655 |
| 30 | Innsbruck | 1976 | 0 | 30 | 1976 Winter | Innsbruck | 1861 |
| 31 | Montreal | 1976 | 1 | 31 | 1976 Summer | Montreal | 8641 |
| 32 | Lake Placid | 1980 | 0 | 32 | 1980 Winter | Lake Placid | 1746 |
| 33 | Moscow | 1980 | 1 | 33 | 1980 Summer | Moskva | 7191 |
| 34 | Los Angeles | 1984 | 1 | 34 | 1984 Summer | Los Angeles | 9454 |
| 35 | Sarajevo | 1984 | 0 | 35 | 1984 Winter | Sarajevo | 2134 |
| 36 | Calgary | 1988 | 0 | 36 | 1988 Winter | Calgary | 2639 |
| 37 | Seoul | 1988 | 1 | 37 | 1988 Summer | Seoul | 12037 |
| 38 | Albertville | 1992 | 0 | 38 | 1992 Winter | Albertville | 3436 |
| 39 | Barcelona | 1992 | 1 | 39 | 1992 Summer | Barcelona | 12977 |
| 40 | Lillehammer | 1994 | 0 | 40 | 1994 Winter | Lillehammer | 3160 |
| 41 | Atlanta | 1996 | 1 | 41 | 1996 Summer | Atlanta | 13780 |
| 42 | Nagano | 1998 | 0 | 42 | 1998 Winter | Nagano | 3605 |
| 43 | Sydney | 2000 | 1 | 43 | 2000 Summer | Sydney | 13821 |
| 44 | Salt Lake City | 2002 | 0 | 44 | 2002 Winter | Salt Lake City | 4109 |
| 45 | Athens | 2004 | 1 | 45 | 2004 Summer | Athina | 13443 |
| 46 | Turin | 2006 | 0 | 46 | 2006 Winter | Torino | 4382 |
| 47 | Beijing | 2008 | 1 | 47 | 2008 Summer | Beijing | 13602 |
| 48 | Vancouver | 2010 | 0 | 48 | 2010 Winter | Vancouver | 4402 |
| 49 | London | 2012 | 1 | 49 | 2012 Summer | London | 12920 |
| 50 | Sochi | 2014 | 0 | 50 | 2014 Winter | Sochi | 4891 |
| 51 | Rio de Janeiro | 2016 | 1 | 51 | 2016 Summer | Rio de Janeiro | 13688 |
import re
# starts with a digit (at start of string) or '.'- goes on for undefinable length
regex_pattern=r'^[\d|.]*'
# starts with a comma then spaces then digits or '.'
regex_pattern2=',\s*[\d|.|]*'
test_string = df_games.iloc[1,-2]
print(test_string)
a=re.search(regex_pattern2, test_string)
for i in range(len(df_games)):
# print(df_games.iloc[i,-2])
try:
df_games.iloc[i,-1]= re.search(regex_pattern2,df_games.iloc[i,-2])[0][2:]
df_games.iloc[i,-2]= re.search(regex_pattern,df_games.iloc[i,-2])[0]
except:
pass48.8566° N, 2.3522°def getNation(region_to_check):
import re
if region_to_check=='United States':
region_out = 'USA'
elif bool(re.search(r'Germany', region_to_check)):
region_out='Germany'
elif region_to_check=='United Kingdom':
region_out = 'UK'
elif region_to_check=='Soviet Union':
region_out='Russia'
else:
region_out=region_to_check
print('nothing found for {}'.format(region_out))
return region_out
for i in range(len(df_games)):
x=df2[df2.region==df_games.iloc[i,2]].region
if len(x)<1:
x=df2[df2.notes==df_games.iloc[i,2]].region
if len(x)<1:
x=getNation(df_games.iloc[i,2])
#
try:
df_games.iloc[i,2]=str(x.iloc[0])
except:
df_games.iloc[i,2]=str(x)
# print(x)
# if len(x)<1:
# print('----------------------------------')
df_games.iloc[10:20,:]| games_id | City | Country | Year | Region | Summer | Winter | Latitude | Longitude | |
|---|---|---|---|---|---|---|---|---|---|
| 10 | 10 | St. Moritz | Switzerland | 1928 | Europe | 0 | 1 | 46.4908 | 9.8355 |
| 11 | 11 | Lake Placid | USA | 1932 | North America | 0 | 1 | 27.2931 | 81.3629 |
| 12 | 12 | Los Angeles | USA | 1932 | North America | 1 | 0 | 34.0522 | 118.2437 |
| 13 | 13 | Berlin | Germany | 1936 | Europe | 1 | 0 | 52.5200 | 13.4050 |
| 14 | 14 | Garmisch-Partenkirchen | Germany | 1936 | Europe | 0 | 1 | 47.4919 | 11.0948 |
| 15 | 15 | London | UK | 1948 | Europe | 1 | 0 | 51.5072 | 0.1276 |
| 16 | 16 | St. Moritz | Switzerland | 1948 | Europe | 0 | 1 | 46.4908 | 9.8355 |
| 17 | 17 | Helsinki | Finland | 1952 | Europe | 1 | 0 | 60.1699 | 24.9384 |
| 18 | 18 | Oslo | Norway | 1952 | Europe | 0 | 1 | 59.9139 | 10.7522 |
| 19 | 19 | Cortina d'Ampezzo | Italy | 1956 | Europe | 0 | 1 | 46.5405 | 12.1357 |
df.groupby(['games_id','Year','Games','City']).count().reset_index()| games_id | Year | Games | City | event_athlete_ID | event_athlete_ID | event_id | athlete_ID | Name | Sex | Age | Height | Weight | Team | NOC | Season | Sport | Event | Medal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1896 | 1896 Summer | Athina | 380 | 380 | 380 | 380 | 380 | 380 | 217 | 46 | 49 | 380 | 380 | 380 | 380 | 380 | 143 |
| 1 | 1 | 1900 | 1900 Summer | Paris | 1936 | 1936 | 1936 | 1936 | 1936 | 1936 | 1146 | 116 | 79 | 1936 | 1936 | 1936 | 1936 | 1936 | 604 |
| 2 | 2 | 1904 | 1904 Summer | St. Louis | 1301 | 1301 | 1301 | 1301 | 1301 | 1301 | 1027 | 213 | 147 | 1301 | 1301 | 1301 | 1301 | 1301 | 486 |
| 3 | 3 | 1906 | 1906 Summer | Athina | 1733 | 1733 | 1733 | 1733 | 1733 | 1733 | 990 | 257 | 205 | 1733 | 1733 | 1733 | 1733 | 1733 | 458 |
| 4 | 4 | 1908 | 1908 Summer | London | 3101 | 3101 | 3101 | 3101 | 3101 | 3101 | 2452 | 475 | 483 | 3101 | 3101 | 3101 | 3101 | 3101 | 831 |
| 5 | 5 | 1912 | 1912 Summer | Stockholm | 4040 | 4040 | 4040 | 4040 | 4040 | 4040 | 3884 | 721 | 596 | 4040 | 4040 | 4040 | 4040 | 4040 | 941 |
| 6 | 6 | 1920 | 1920 Summer | Antwerpen | 4292 | 4292 | 4292 | 4292 | 4292 | 4292 | 3447 | 767 | 471 | 4292 | 4292 | 4292 | 4292 | 4292 | 1308 |
| 7 | 7 | 1924 | 1924 Winter | Chamonix | 460 | 460 | 460 | 460 | 460 | 460 | 403 | 89 | 41 | 460 | 460 | 460 | 460 | 460 | 130 |
| 8 | 8 | 1924 | 1924 Summer | Paris | 5233 | 5233 | 5233 | 5233 | 5233 | 5233 | 4148 | 885 | 649 | 5233 | 5233 | 5233 | 5233 | 5233 | 832 |
| 9 | 9 | 1928 | 1928 Summer | Amsterdam | 4992 | 4992 | 4992 | 4992 | 4992 | 4992 | 4119 | 853 | 670 | 4992 | 4992 | 4992 | 4992 | 4992 | 734 |
| 10 | 10 | 1928 | 1928 Winter | Sankt Moritz | 582 | 582 | 582 | 582 | 582 | 582 | 492 | 122 | 48 | 582 | 582 | 582 | 582 | 582 | 89 |
| 11 | 11 | 1932 | 1932 Winter | Lake Placid | 352 | 352 | 352 | 352 | 352 | 352 | 329 | 196 | 55 | 352 | 352 | 352 | 352 | 352 | 92 |
| 12 | 12 | 1932 | 1932 Summer | Los Angeles | 2969 | 2969 | 2969 | 2969 | 2969 | 2969 | 2662 | 1017 | 495 | 2969 | 2969 | 2969 | 2969 | 2969 | 647 |
| 13 | 13 | 1936 | 1936 Summer | Berlin | 6506 | 6506 | 6506 | 6506 | 6506 | 6506 | 6304 | 1056 | 909 | 6506 | 6506 | 6506 | 6506 | 6506 | 917 |
| 14 | 14 | 1936 | 1936 Winter | Garmisch-Partenkirchen | 895 | 895 | 895 | 895 | 895 | 895 | 884 | 136 | 78 | 895 | 895 | 895 | 895 | 895 | 108 |
| 15 | 15 | 1948 | 1948 Summer | London | 6405 | 6405 | 6405 | 6405 | 6405 | 6405 | 5233 | 1053 | 1040 | 6405 | 6405 | 6405 | 6405 | 6405 | 852 |
| 16 | 16 | 1948 | 1948 Winter | Sankt Moritz | 1075 | 1075 | 1075 | 1075 | 1075 | 1075 | 1071 | 116 | 111 | 1075 | 1075 | 1075 | 1075 | 1075 | 135 |
| 17 | 17 | 1952 | 1952 Summer | Helsinki | 8270 | 8270 | 8270 | 8270 | 8270 | 8270 | 7993 | 2038 | 2038 | 8270 | 8270 | 8270 | 8270 | 8270 | 897 |
| 18 | 18 | 1952 | 1952 Winter | Oslo | 1088 | 1088 | 1088 | 1088 | 1088 | 1088 | 1088 | 150 | 149 | 1088 | 1088 | 1088 | 1088 | 1088 | 136 |
| 19 | 19 | 1956 | 1956 Winter | Cortina d'Ampezzo | 1307 | 1307 | 1307 | 1307 | 1307 | 1307 | 1282 | 344 | 342 | 1307 | 1307 | 1307 | 1307 | 1307 | 150 |
| 20 | 20 | 1956 | 1956 Summer | Melbourne | 4829 | 4829 | 4829 | 4829 | 4829 | 4829 | 4256 | 2234 | 2232 | 4829 | 4829 | 4829 | 4829 | 4829 | 857 |
| 21 | 21 | 1956 | 1956 Summer | Stockholm | 298 | 298 | 298 | 298 | 298 | 298 | 258 | 108 | 106 | 298 | 298 | 298 | 298 | 298 | 36 |
| 22 | 22 | 1960 | 1960 Summer | Roma | 8119 | 8119 | 8119 | 8119 | 8119 | 8119 | 7906 | 7738 | 7675 | 8119 | 8119 | 8119 | 8119 | 8119 | 911 |
| 23 | 23 | 1960 | 1960 Winter | Squaw Valley | 1116 | 1116 | 1116 | 1116 | 1116 | 1116 | 1108 | 536 | 512 | 1116 | 1116 | 1116 | 1116 | 1116 | 147 |
| 24 | 24 | 1964 | 1964 Winter | Innsbruck | 1778 | 1778 | 1778 | 1778 | 1778 | 1778 | 1765 | 1369 | 1348 | 1778 | 1778 | 1778 | 1778 | 1778 | 186 |
| 25 | 25 | 1964 | 1964 Summer | Tokyo | 7702 | 7702 | 7702 | 7702 | 7702 | 7702 | 7659 | 7430 | 7424 | 7702 | 7702 | 7702 | 7702 | 7702 | 1029 |
| 26 | 26 | 1968 | 1968 Winter | Grenoble | 1891 | 1891 | 1891 | 1891 | 1891 | 1891 | 1872 | 1833 | 1817 | 1891 | 1891 | 1891 | 1891 | 1891 | 199 |
| 27 | 27 | 1968 | 1968 Summer | Mexico City | 8588 | 8588 | 8588 | 8588 | 8588 | 8588 | 8489 | 8493 | 8493 | 8588 | 8588 | 8588 | 8588 | 8588 | 1057 |
| 28 | 28 | 1972 | 1972 Summer | Munich | 10304 | 10304 | 10304 | 10304 | 10304 | 10304 | 10211 | 10018 | 9928 | 10304 | 10304 | 10304 | 10304 | 10304 | 1215 |
| 29 | 29 | 1972 | 1972 Winter | Sapporo | 1655 | 1655 | 1655 | 1655 | 1655 | 1655 | 1652 | 1640 | 1642 | 1655 | 1655 | 1655 | 1655 | 1655 | 199 |
| 30 | 30 | 1976 | 1976 Winter | Innsbruck | 1861 | 1861 | 1861 | 1861 | 1861 | 1861 | 1850 | 1343 | 1302 | 1861 | 1861 | 1861 | 1861 | 1861 | 211 |
| 31 | 31 | 1976 | 1976 Summer | Montreal | 8641 | 8641 | 8641 | 8641 | 8641 | 8641 | 8600 | 8283 | 8280 | 8641 | 8641 | 8641 | 8641 | 8641 | 1320 |
| 32 | 32 | 1980 | 1980 Winter | Lake Placid | 1746 | 1746 | 1746 | 1746 | 1746 | 1746 | 1745 | 1388 | 1374 | 1746 | 1746 | 1746 | 1746 | 1746 | 218 |
| 33 | 33 | 1980 | 1980 Summer | Moskva | 7191 | 7191 | 7191 | 7191 | 7191 | 7191 | 7005 | 6961 | 6967 | 7191 | 7191 | 7191 | 7191 | 7191 | 1384 |
| 34 | 34 | 1984 | 1984 Summer | Los Angeles | 9454 | 9454 | 9454 | 9454 | 9454 | 9454 | 9249 | 9032 | 9031 | 9454 | 9454 | 9454 | 9454 | 9454 | 1476 |
| 35 | 35 | 1984 | 1984 Winter | Sarajevo | 2134 | 2134 | 2134 | 2134 | 2134 | 2134 | 2123 | 1958 | 1954 | 2134 | 2134 | 2134 | 2134 | 2134 | 222 |
| 36 | 36 | 1988 | 1988 Winter | Calgary | 2639 | 2639 | 2639 | 2639 | 2639 | 2639 | 2635 | 2024 | 2018 | 2639 | 2639 | 2639 | 2639 | 2639 | 263 |
| 37 | 37 | 1988 | 1988 Summer | Seoul | 12037 | 12037 | 12037 | 12037 | 12037 | 12037 | 11931 | 11719 | 11730 | 12037 | 12037 | 12037 | 12037 | 12037 | 1582 |
| 38 | 38 | 1992 | 1992 Winter | Albertville | 3436 | 3436 | 3436 | 3436 | 3436 | 3436 | 3435 | 2785 | 2783 | 3436 | 3436 | 3436 | 3436 | 3436 | 318 |
| 39 | 39 | 1992 | 1992 Summer | Barcelona | 12977 | 12977 | 12977 | 12977 | 12977 | 12977 | 12934 | 10453 | 10473 | 12977 | 12977 | 12977 | 12977 | 12977 | 1712 |
| 40 | 40 | 1994 | 1994 Winter | Lillehammer | 3160 | 3160 | 3160 | 3160 | 3160 | 3160 | 3158 | 2973 | 2971 | 3160 | 3160 | 3160 | 3160 | 3160 | 331 |
| 41 | 41 | 1996 | 1996 Summer | Atlanta | 13780 | 13780 | 13780 | 13780 | 13780 | 13780 | 13772 | 11909 | 11959 | 13780 | 13780 | 13780 | 13780 | 13780 | 1842 |
| 42 | 42 | 1998 | 1998 Winter | Nagano | 3605 | 3605 | 3605 | 3605 | 3605 | 3605 | 3603 | 3521 | 3519 | 3605 | 3605 | 3605 | 3605 | 3605 | 440 |
| 43 | 43 | 2000 | 2000 Summer | Sydney | 13821 | 13821 | 13821 | 13821 | 13821 | 13821 | 13820 | 13698 | 13695 | 13821 | 13821 | 13821 | 13821 | 13821 | 2004 |
| 44 | 44 | 2002 | 2002 Winter | Salt Lake City | 4109 | 4109 | 4109 | 4109 | 4109 | 4109 | 4109 | 4080 | 4062 | 4109 | 4109 | 4109 | 4109 | 4109 | 478 |
| 45 | 45 | 2004 | 2004 Summer | Athina | 13443 | 13443 | 13443 | 13443 | 13443 | 13443 | 13443 | 13407 | 13406 | 13443 | 13443 | 13443 | 13443 | 13443 | 2001 |
| 46 | 46 | 2006 | 2006 Winter | Torino | 4382 | 4382 | 4382 | 4382 | 4382 | 4382 | 4382 | 4376 | 4366 | 4382 | 4382 | 4382 | 4382 | 4382 | 526 |
| 47 | 47 | 2008 | 2008 Summer | Beijing | 13602 | 13602 | 13602 | 13602 | 13602 | 13602 | 13600 | 13451 | 13443 | 13602 | 13602 | 13602 | 13602 | 13602 | 2048 |
| 48 | 48 | 2010 | 2010 Winter | Vancouver | 4402 | 4402 | 4402 | 4402 | 4402 | 4402 | 4402 | 4400 | 4378 | 4402 | 4402 | 4402 | 4402 | 4402 | 520 |
| 49 | 49 | 2012 | 2012 Summer | London | 12920 | 12920 | 12920 | 12920 | 12920 | 12920 | 12920 | 12752 | 12560 | 12920 | 12920 | 12920 | 12920 | 12920 | 1941 |
| 50 | 50 | 2014 | 2014 Winter | Sochi | 4891 | 4891 | 4891 | 4891 | 4891 | 4891 | 4891 | 4871 | 4673 | 4891 | 4891 | 4891 | 4891 | 4891 | 597 |
| 51 | 51 | 2016 | 2016 Summer | Rio de Janeiro | 13688 | 13688 | 13688 | 13688 | 13688 | 13688 | 13688 | 13512 | 13465 | 13688 | 13688 | 13688 | 13688 | 13688 | 2023 |
Create some smaller athlete tables
Finally the main athletes df file can be split the up by sex and season, since the id’s for different fields have been added
- We don’t really need sex and Season so we can drop these
- We can also reorder the index (not the athlete ID)
- If Medals = NaN this probably means they didn’t get one. So we can replace medals with Gold, Silver and Bronze (one-hot encoding)
- Instead of Games, Year, City lets replace with a uniques INT id. And put that data in another dataframe for cities
# split and Reset index, so it increases 1,2,3,4,etc
df_M_S = df[(df.Sex=='M') & (df.Season=='Summer')]
df_M_S.reset_index(inplace = True,drop=True)
df_F_S = df[(df.Sex=='F') & (df.Season=='Summer')]
df_F_S.reset_index(inplace = True,drop=True)
df_M_W = df[(df.Sex=='M') & (df.Season=='Winter')]
df_M_W.reset_index(inplace = True,drop=True)
df_F_W = df[(df.Sex=='F') & (df.Season=='Winter')]
df_F_W.reset_index(inplace = True,drop=True)# Look at the data
df_M_W.head(10)| event_athlete_ID | event_athlete_ID | event_id | games_id | athlete_ID | Name | Sex | Age | Height | Weight | Team | NOC | Games | Year | Season | City | Sport | Event | Medal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 672 | 672 | 13 | 7 | 391 | Clarence John Abel | M | 23.0 | 185.0 | 102.0 | United States | USA | 1924 Winter | 1924 | Winter | Chamonix | Ice Hockey | Ice Hockey Men's Ice Hockey | Silver |
| 1 | 1791 | 1791 | 205 | 7 | 992 | Josef Adolf | M | 25.0 | NaN | NaN | Czechoslovakia | BOH | 1924 Winter | 1924 | Winter | Chamonix | Nordic Combined | Nordic Combined Men's Individual | NaN |
| 2 | 1951 | 1951 | 300 | 7 | 1077 | Xavier Affentranger | M | 26.0 | NaN | NaN | Switzerland | SUI | 1924 Winter | 1924 | Winter | Chamonix | Ski Jumping | Ski Jumping Men's Normal Hill, Individual | NaN |
| 3 | 1952 | 1952 | 385 | 7 | 1077 | Xavier Affentranger | M | 26.0 | NaN | NaN | Switzerland | SUI | 1924 Winter | 1924 | Winter | Chamonix | Cross Country Skiing | Cross Country Skiing Men's 18 kilometres | NaN |
| 4 | 1953 | 1953 | 205 | 7 | 1077 | Xavier Affentranger | M | 26.0 | NaN | NaN | Switzerland | SUI | 1924 Winter | 1924 | Winter | Chamonix | Nordic Combined | Nordic Combined Men's Individual | NaN |
| 5 | 2397 | 2397 | 305 | 7 | 1341 | Johan Petter hln (Andersson-) | M | 44.0 | NaN | NaN | Sweden | SWE | 1924 Winter | 1924 | Winter | Chamonix | Curling | Curling Men's Curling | Silver |
| 6 | 4040 | 4040 | 300 | 7 | 2329 | Louis Albert | M | 25.0 | NaN | NaN | France | FRA | 1924 Winter | 1924 | Winter | Chamonix | Ski Jumping | Ski Jumping Men's Normal Hill, Individual | NaN |
| 7 | 4249 | 4249 | 472 | 7 | 2431 | Henri Eugne Aldebert | M | 43.0 | NaN | NaN | France-1 | FRA | 1924 Winter | 1924 | Winter | Chamonix | Bobsleigh | Bobsleigh Men's Four/Five | NaN |
| 8 | 5103 | 5103 | 13 | 7 | 2902 | Karl Ruben Allinger | M | 32.0 | NaN | NaN | Sweden | SWE | 1924 Winter | 1924 | Winter | Chamonix | Ice Hockey | Ice Hockey Men's Ice Hockey | NaN |
| 9 | 5174 | 5174 | 7 | 7 | 2939 | Ernst Alm | M | 23.0 | 174.0 | NaN | Sweden | SWE | 1924 Winter | 1924 | Winter | Chamonix | Cross Country Skiing | Cross Country Skiing Men's 50 kilometres | NaN |
df_M_S = df_M_S.drop(columns=['Name','Sex','Season','City','Games','Sport','Event'])
df_F_S = df_F_S.drop(columns=['Name','Sex','Season','City','Games','Sport','Event'])
df_M_W = df_M_W.drop(columns=['Name','Sex','Season','City','Games','Sport','Event'])
df_F_W = df_F_W.drop(columns=['Name','Sex','Season','City','Games','Sport','Event'])
df_F_W.head(5)| event_athlete_ID | event_athlete_ID | event_id | games_id | athlete_ID | Age | Height | Weight | Team | NOC | Year | Medal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 30620 | 30620 | 268 | 7 | 15776 | 22.0 | 165.0 | NaN | France | FRA | 1924 | NaN |
| 1 | 30621 | 30621 | 242 | 7 | 15776 | 22.0 | 165.0 | NaN | France-1 | FRA | 1924 | Bronze |
| 2 | 63714 | 63714 | 242 | 7 | 32641 | 25.0 | NaN | NaN | Austria | AUT | 1924 | Gold |
| 3 | 94058 | 94058 | 268 | 7 | 47618 | 11.0 | 155.0 | 45.0 | Norway | NOR | 1924 | NaN |
| 4 | 94533 | 94533 | 242 | 7 | 47845 | NaN | NaN | NaN | Belgium | BEL | 1924 | NaN |
Seperate out medals
df_F_W = pd.get_dummies(df_F_W,columns=['Medal'])
df_M_W = pd.get_dummies(df_M_W,columns=['Medal'])
df_F_S = pd.get_dummies(df_F_S,columns=['Medal'])
df_M_S = pd.get_dummies(df_M_S,columns=['Medal'])
df_M_S.head()| event_athlete_ID | event_athlete_ID | event_id | games_id | athlete_ID | Age | Height | Weight | Team | NOC | Year | Medal_Bronze | Medal_Gold | Medal_Silver | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3079 | 3079 | 191 | 0 | 1724 | NaN | NaN | NaN | Greece | CRT | 1896 | 0 | 0 | 0 |
| 1 | 3080 | 3080 | 92 | 0 | 1724 | NaN | NaN | NaN | Greece-3 | CRT | 1896 | 0 | 0 | 0 |
| 2 | 3081 | 3081 | 191 | 0 | 1725 | NaN | NaN | NaN | Greece | CRT | 1896 | 0 | 0 | 0 |
| 3 | 3082 | 3082 | 92 | 0 | 1725 | NaN | NaN | NaN | Greece-3 | CRT | 1896 | 0 | 0 | 0 |
| 4 | 7348 | 7348 | 100 | 0 | 4113 | NaN | NaN | NaN | Greece | CRT | 1896 | 0 | 0 | 0 |
Save it
df_F_S.to_csv('athlete_F_S')
df_F_W.to_csv('athlete_F_W')
df_M_S.to_csv('athlete_M_S')
df_M_W.to_csv('athlete_M_W')
df_all_athletes.to_csv('all_athletes')
df_country.to_csv('country')
df_event.to_csv('event')
df_games.to_csv('games')
df_population.to_csv('population')