# current directory
path=Path()
Path.BASE_PATH = path
# another folder off cwd
path = Path('bears')
#if doesn't exist can do
path.mkdir()
# as part of downloading inbuilt data
path = untar_data(URLs.IMDB)
# When using path to select a subfolder
`trains = path/'train'`
Or to view
`(path/'train').ls()FastAI CheatSheet
Using FastAI

Misc.
Creating a path
Where the data is
Loading the data
DataLoaders is a thin class that just stores whatever DataLoader objects you pass to it, and makes them available as train and valid. Although it’s a very simple class, it’s very important in fastai: it provides the data for your model. The key functionality in DataLoaders is provided with just these four lines of code (it has some other minor functionality we’ll skip over for now):
class DataLoaders(GetAttr):
def __init__(self, *loaders): self.loaders = loaders
def __getitem__(self, i): return self.loaders[i]
train,valid = add_props(lambda i,self: self[i])To turn our downloaded data into a DataLoaders object we need to tell fastai at least four things:
- What kinds of data we are working with
- How to get the list of items
- How to label these items
- How to create the validation set
DataBlocks
dBlock = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=Resize(128))blocks what format is the data? - ImageBlock - CategoryBlock - TextBlock
get_items takes a function that that gives the list of all data (images/text etc) - get_image_files - partial(get_text_files, folders=['train', 'test', 'unsup'])
splitter how data is plit into test and validation sets - RandomSplitter(valid_pct=0.2, seed=42) randomly - def splitter(df): train = df.index[~df['is_valid']].tolist() valid = df.index[df['is_valid']].tolist() return train,valid use a function this one uses data frame
get_x and get_y get the independent (x) and dependent variables (y) takes a function that provides labels for the data - parent_label gets the name of the parent folder e.g. when doing categorical data put rabbits in ‘rabbits’ folder and horses in ‘horses’ folder - def get_y(r): return r['labels'].split(' ')
item_tfms runs on individual items- allows for data augmentation, making images the same size etc - Resize(128) resize all images to 128 - Resize(128, ResizeMethod.Pad, pad_mode='zeros' resize with zeros
batch_tfms similar to the above but apply to all batch - [*aug_transforms(size=size, min_scale=0.75), Normalize.from_stats(*imagenet_stats)]
DataLoaders
The data block is like a template for creating a DataLoaders. We still need to tell fastai the actual source of our data—in this case, the path where the images can be found along with some other details.
A DataLoaders includes validation and training DataLoaders. DataLoader is a class that provides batches of a few items at a time to the GPU. When you loop through a DataLoader fastai will give you 64 (by default) items at a time, all stacked up into a single tensor.
dls = dBlock.dataloaders(path,
path=path,
bs=128,
seq_len=80)after_item applied after each item equivalent of item_tfms
before_batch applied on list of items before they’re collated
after_batch applied on the batch as a whole after construction- equivalent to batch_tfms
bs batch size
seq_len
path path to data
The model
Different models
Vision
from fastai.vision import models
learn = cnn_learner(data, models.resnet18, metrics=accuracy)
Torchvision models
resnet18,resnet34,resnet50,resnet101,resnet152squeezenet1_0,squeezenet1_1densenet121,densenet169,densenet201,densenet161vgg16_bn,vgg19_bnalexnetOthersDarknetunet
Text
from fastai.text import *
learn = language_model_learner(data_lm, AWD_LSTM, drop_mult=0.5)
Or for classification
learn = text_classifier_learner(data_clas, AWD_LSTM, drop_mult=0.5)
Tabular
from fastai.tabular import *
learn = tabular_learner(data, layers=[200,100], emb_szs={'native-country': 10}, metrics=accuracy)
Learning
To fit the model we have a few options:
learn.fit(10,lr=4e-3)learn.fit_one_cycle()learn.fine_tune(10, base_lr=1e-3, freeze_epochs=7)learn.fine_tune(15, lr)
FastAI adds an extra 2 layers on the end of neural network when doing transfer learning, these can then be fitted using fine_tune. It is recommended to do a few fits frozen before unfreezing. This is normally the best option for transfer learning.
But the other ones can be used. In general fit can be more unstable and lead to bigger losses, but can be useful if fine_tune is not bringing losses down.
https://forums.fast.ai/t/fine-tune-vs-fit-one-cycle/66029/6
fit_one_cycle = New Model
fine_tuning = with Transfer Learning?
I’d say yes but with a very strong but, only because it’s easy to fall into a trap that way. fine_tuning is geared towards transfer learning specifically, but you can also just do fit_one_cycle as well! (Or flat_cos).
For beginners it’s a great starting fit function (and advanced too), but also don’t forget that you can thenAn alternative to fine_tuning with transfer learning is to specify which layers are frozen:
Unfreeze layers, to freeze all except the last two parameter groups use freeze_to:
learn.freeze_to(-2)
learn.fit_one_cycle(1, slice(1e-2/(2.6**4),1e-2))
And unfreeze a bit more
learn.freeze_to(-3)
Or unfreeze the whole model
learn.unfreeze
Can see the difference between fine_tune and fit_one_cycle from the fine_tune function:
def fine_tune(self:Learner, epochs, base_lr=2e-3, freeze_epochs=1, lr_mult=100,
pct_start=0.3, div=5.0, **kwargs):
"Fine tune with `freeze` for `freeze_epochs` then with `unfreeze` from `epochs` using discriminative LR"
self.freeze()
self.fit_one_cycle(freeze_epochs, slice(base_lr), pct_start=0.99, **kwargs)
base_lr /= 2
self.unfreeze()
self.fit_one_cycle(epochs, slice(base_lr/lr_mult, base_lr), pct_start=pct_start, div=div, **kwargs)Some other useful bits
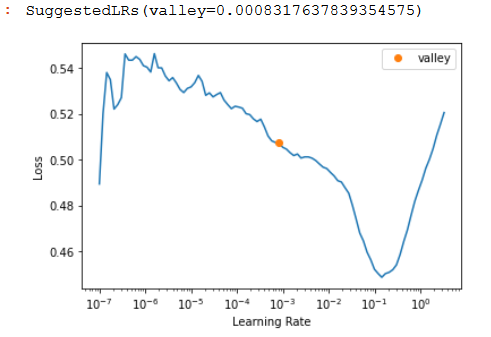
Find the best learing rate:
learn.lr_find()